
With only a few days to go till WWDC 2025, Apple printed a new AI study that would mark a turning level for the way forward for AI as we transfer nearer to AGI.
Apple created checks that reveal reasoning AI fashions accessible to the general public don’t actually reason. These fashions produce spectacular leads to math issues and different duties as a result of they’ve seen these kinds of checks throughout coaching. They’ve memorized the steps to resolve issues or full numerous duties customers would possibly give to a chatbot.
However Apple’s personal checks confirmed that these AI fashions can’t adapt to unfamiliar issues and determine options. Worse, the AI tends to surrender if it fails to resolve a activity. Even when Apple offered the algorithms within the prompts, the chatbots nonetheless couldn’t go the checks.
Apple researchers didn’t use math issues to evaluate whether or not high AI fashions can reason. As a substitute, they turned to puzzles to check numerous fashions’ reasoning talents.
The tests included puzzles like Tower of Hanoi, Checker Leaping, River Crossing, and Blocks World. Apple evaluated each common massive language fashions (LLMs) and huge reasoning fashions (LRMs) utilizing these puzzles, adjusting the problem ranges.
Apple examined LLMs like ChatGPT GPT-4, Claude 3.7 Sonnet, and DeepSeek V3. For LRMs, it examined ChatGPT o1, ChatGPT o3-mini, Gemini, Claude 3.7 Sonnet Pondering, and DeepSeek R1.
The scientists discovered that LLMs carried out higher than reasoning fashions when the problem was simple. LRMs did higher at medium problem. As soon as the duties reached the exhausting stage, all fashions failed to finish them.
Apple noticed that the AI fashions merely gave up on fixing the puzzles at tougher ranges. Accuracy didn’t simply decline steadily, it collapsed outright.
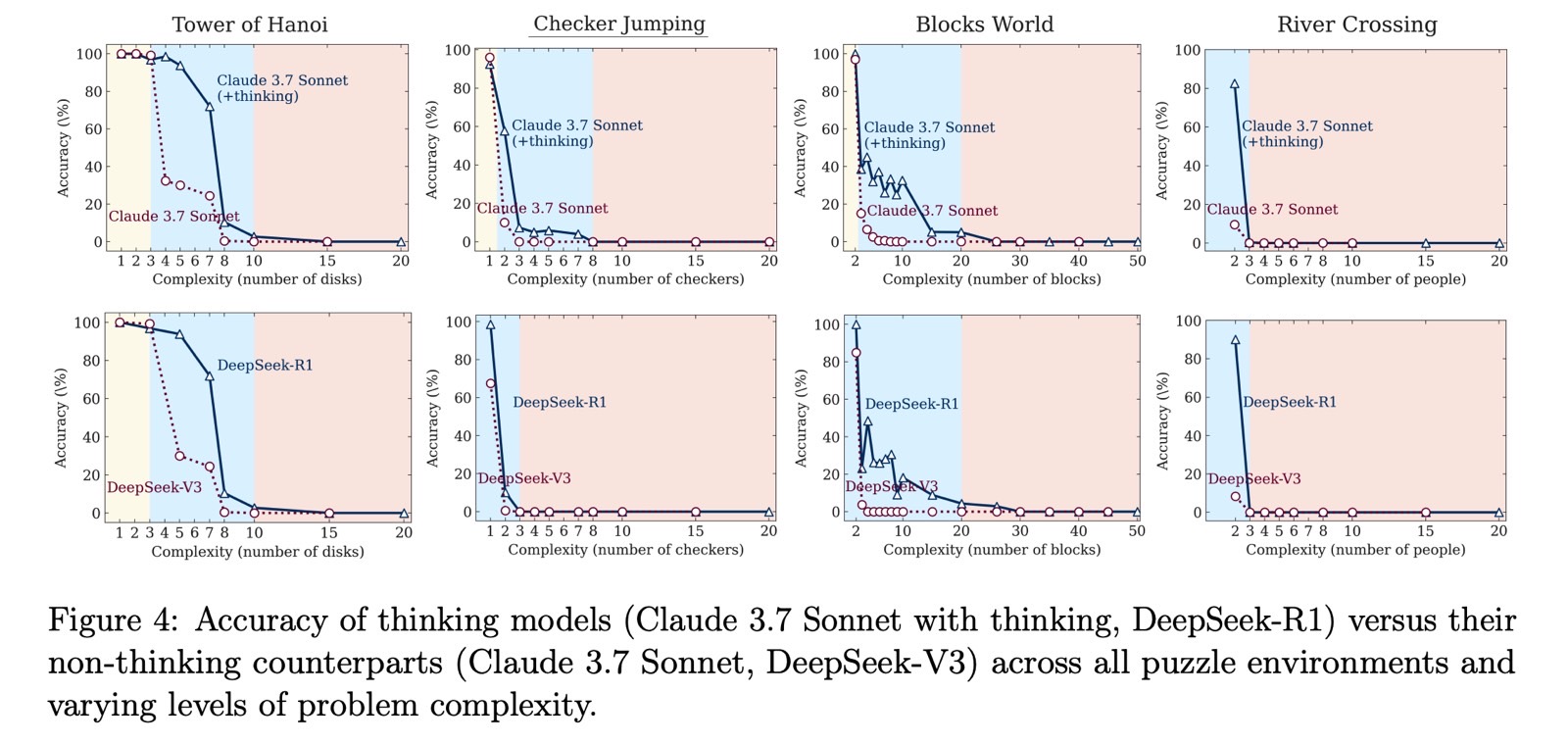
The study means that even the very best reasoning AI fashions don’t actually reason when confronted with unfamiliar puzzles. The thought of “reasoning” on this context is deceptive since these fashions aren’t really pondering.
The Apple researchers added that experiments like theirs might result in additional analysis aimed at growing higher reasoning AI fashions down the highway.
Then once more, many people already suspected that reasoning AI fashions don’t actually assume. AGI, or synthetic common intelligence, can be the sort of AI that may determine issues out by itself when dealing with new challenges.
I’ll additionally level out the plain “grapes are bitter” angle right here. Apple’s study may be a breakthrough, certain. Nevertheless it comes at a time when Apple Intelligence isn’t actually aggressive with ChatGPT, Gemini, and different mainstream AI fashions. Overlook reasoning—Siri can’t even let you know what month it’s. I’d select ChatGPT o3 over Siri any day.
The timing of the study’s launch can also be questionable. Apple is about to host its annual WWDC 2025, and AI received’t be the principle focus. Apple nonetheless trails OpenAI, Google, and different AI firms which have launched industrial reasoning fashions. That’s not essentially a nasty factor, particularly provided that Apple continues to publish research that showcase its personal analysis and concepts within the subject.
Nonetheless, Apple is principally saying that reasoning AI fashions aren’t as succesful as folks would possibly imagine, simply days earlier than an occasion the place it received’t have any main AI developments to announce. That’s effective too. I say this as a longtime iPhone consumer who nonetheless thinks Apple Intelligence has potential to catch up.
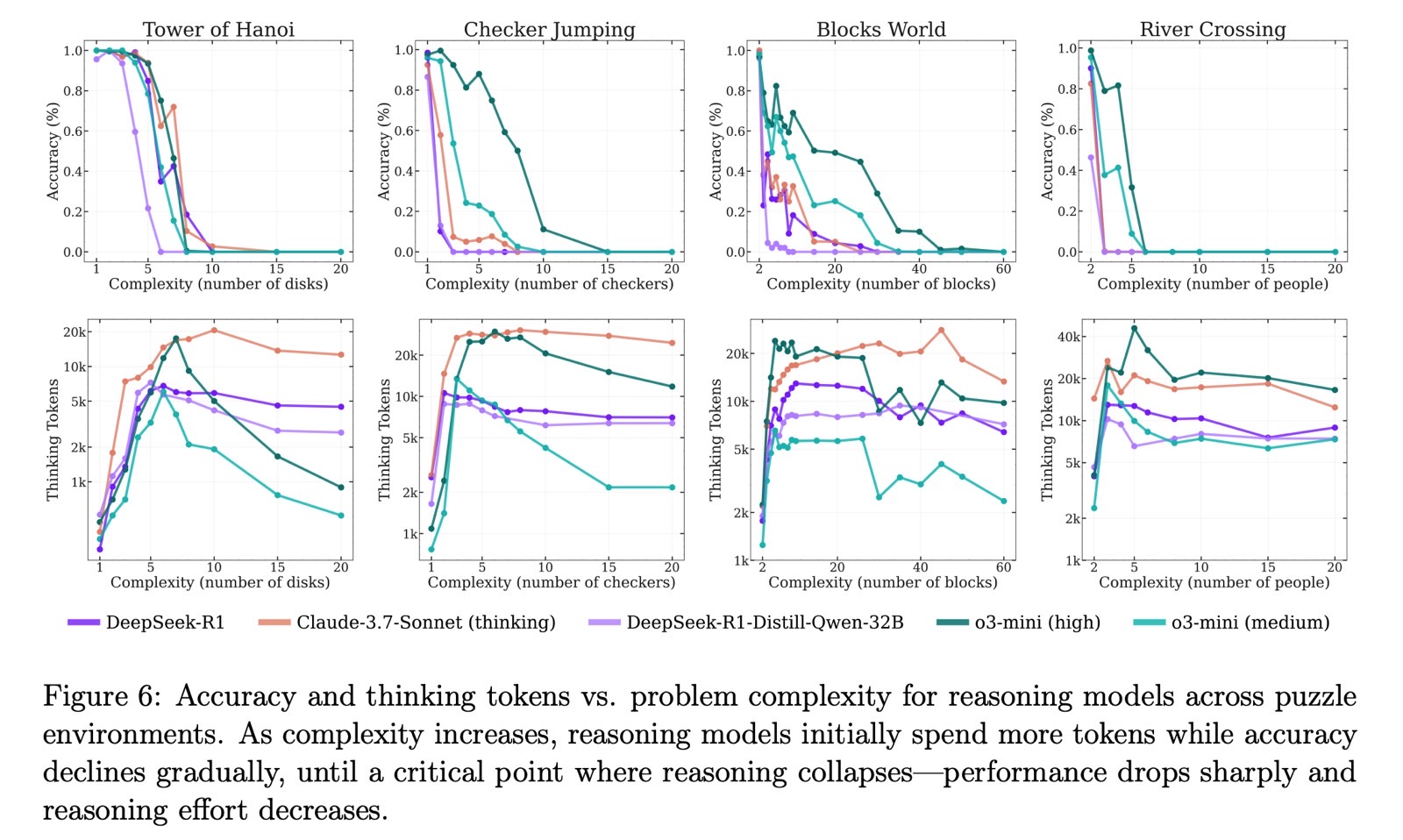
The study’s findings are essential, and I’m certain others will attempt to confirm or problem them. Some would possibly even use these insights to enhance their very own reasoning fashions. Nonetheless, it does really feel odd to see Apple downplay reasoning AI fashions proper earlier than WWDC.
I’ll additionally say this: as a ChatGPT o3 consumer, I’m not giving up on reasoning fashions even when they will’t really assume. o3 is my present go-to AI, and I like its responses greater than the opposite ChatGPT choices. It makes errors and hallucinates, however its “reasoning” nonetheless feels stronger than what primary LLMs can do.